【西川和久の不定期コラム】動画生成AIが2年前から驚異的な進化を遂げたので、ハロウィンっぽいMVをぜ~んぶAIで作ってみた
アクセスランキング
Special Site
PC Watch をフォローする
最新記事
Impress Watchシリーズ 人気記事
おすすめ記事
2025年夏から秋にかけて、動画生成AIが一気に進化した。そこで今回は「Sora2」などメインどころをピックアップしながらその進化をご紹介。最後にハロウィンっぽいMVをすべてAIで作ってみる。
今年(2025年)秋の状況を説明する前に軽く2023年、2024年も振り返ってみたい。まず2023年12月にi2v(Image to Video)の「Stable Video Diffusion」が登場した。それまでも「AnimateDiff」もあったが、本家のStability AIから出た意味は大きい。
ただご覧のように動画とはいえ紙芝居状態。これでも当時はかなり盛り上がった。なお掲載している動画はすべて後処理でフルHDにアップスケールしている。あらかじめご了承いただきたい。
2024年秋は、サービス系のHailuo AIとローカルのAI PCで生成できる「Mochi Preview」を紹介している。
サービス系のHailuo AIは、1つ5秒とは言えそれなりに出ている。対してMochi Previewは、初めの車はともかくとして以降は全然ダメだ。同じ頃にオープンな「Hunyuan-Video」もあり、こちらは結構マシだったとは言え、サービス系に勝てる感じではなかった。このように2024年秋はまだサービス系とオープン系で結構な開きがあった。
そして2025年夏、オープン系ではWan 2.1と2.2が続けてリリース。この時点でやっと去年のサービス系に追いついた感じだ。
サービス系では「KlingAI」、Midjourneyの動画対応、そのほか数えきれないほどいろいろ出ており、すでにこのレベルは超えている。筆者の感覚的にはオープンなモデルは半年から1年遅れている感じだろうか。
とは言え、ここまでは程度の差こそあれ、基本的にテキストから動画か、画像から動画。音はあっても効果音程度(Veo 3を除く)。似たり寄ったりだった(もちろん一部リップシンクなどもあり)。
そんな中、異様な進化をとげたのが2025年9月末にOpen AIからリリースされたSora2だ。当初は招待制でiPhoneアプリとWebからのみ。後日APIでの利用も可能になった。特徴としては、
- 縦/横、10/15/25(ChatGPT Proユーザーのみ)秒対応
- 参照画像対応。ただしリアルな人の顔が写っているのはフェイク対策上NG
- remixes。公開している(Drafts未対応)動画に対してPromptで一貫性を保ったまま別バージョンを作る
- cameo。アカウントが使用するiPhoneから顔と声を登録して動画に登場できる
- 短いプロンプトや参照画像からシナリオ、シーン、セリフなどを自動的に考え生成
筆者が中でも興味深いのが4と5だ。4は従来t2v(Text to Video)で顔LoRAを使うか、i2vで顔が写っている画像を用意すればできる。ただし前者は似ているとは言え気持ちAI的。後者は顔だけでなく衣服や背景も引きずり、かつ一貫性が保てなくなると崩れる。
ところがこのcameoは、iPhoneで顔の正面左右を撮影、2桁の数字を3つ読み上げる(日本語で良い)だけで、顔も声も酷似する。制限上筆者が作例になってしまうのはお許し願いたいが、本人が驚くほど顔も声もそっくり。何も知らない知人が見れば間違いなく本人のリアル映像と思ってしまうだろう。
加えて、この顔/声データは公開レベルが本人のみ、許可したユーザー、フォロワー、全体と設定でき、たとえば公開している誰かと誰かが話しているような映像も生成可能。実際サイトの中にはこの手の映像が溢れており、特にOpen AIのSam Altman氏が全体公開していることもあり、いじられまくっている(笑)。
5は、筆者の推測であるが、与えたPromptや参照画像からLLMがシナリオ、シーン、セリフなどを考え、それをエンジンに送っていると思われる。歌詞付きの音楽なども凄まじいレベルだ。実際作例をご覧になるとお分かりだとは思うが、従来型だとどう頑張ってもこうはならない。
もちろんザックリなプロンプトだけでなく、秒単位での指定、セリフ、カメラアングル、動き……など、詳しく書けばそれに準じた動画も生成する。
いずれにしても透かしがなければもうAIか?本物か?見分けがつかないレベルになってしまった。
APIを使えば透かしがなくなり、後日対抗馬?としてVeo 3.1もリリースされたが、remixesやcameoがない分、サイト版Sora2のインパクトには及ばない。
意外な伏兵が「Grok Imagine」。XやGrokのアカウントがあれば気軽にt2i、i2vが楽しめ、しかも速く結構な数が作れる。またNano-Bananaのような画像編集機能もある。少し前までクオリティ的にイマイチだったが、ここに来てそのクオリティもグッと上がった。
GrokでImagine(WebUI)かCreate Videos(iOS)を選び、プロンプトで画像を作り、必要であればそこから動画も生成。また画像はユーザーが用意したものをアップロードして使うことも可能だ。つまり前者はt2i2v、後者はi2vとなる。
動画生成時はプロンプトに加え、プリセットのNormal/Fun/Spicy(t2vのみ)が用意され、コントロール自由。さらにセンシティブに関してはかなり寛容だ。ほかのサービス系では絶対通らないワードも普通に通り反映される。プロンプトにセリフを入れれば話すことも可能(英語のみ)。
この動画は筆者がQwen-Imageで作った画像から動画へ変換。4つつなげたものだ。かなり自然に動いているのが分かる。これだけの動画が追加費用なしで作れるなら使わない手はないだろう。
さて、ここまでが2023年冬から現時点での(いろいろ大物も抜けているが)超ザックリな動画生成環境となる。どれも去年からぐっとレベルが上がり、パッと見ではもうリアルな動画と区別がつかないほどになっている。
しかし、表題の“ハロウィンっぽいMVをすべてAIで作る”は無理。理由は声や楽曲を与えることができないからだ。上記はすべてテキストか画像を入力。音に関しては入力できず、これではMVを作りようがない。
つい先日t2s+i2v(テキストから声を生成、+参照画像で動画へ)の「Ovi: Twin Backbone Cross-Modal Fusion for Audio-Video Generation」がComfyUIに乗ったのでこれを試してみた。
入力は映像全体を構成する参照画像。もちろん話すので人(でなくてもいいが)が必要。喋る内容はPromptで指示する。<S><E>に囲まれた分がセリフだ。これで生成すると以下のような動画となる。
A woman exclaiming <S>Now we can generate videos with audio, locally!!<E>. <AUDCAP>Clear female voice speaking dialogue, subtle outdoor ambience.<ENDAUDCAP>
これはこれで面白いのだが、5秒で英語だけではMVは作れないので却下。
次に試したのがWan2.2-S2V。サウンドからビデオ生成、最大720P@24fpsに対応する。
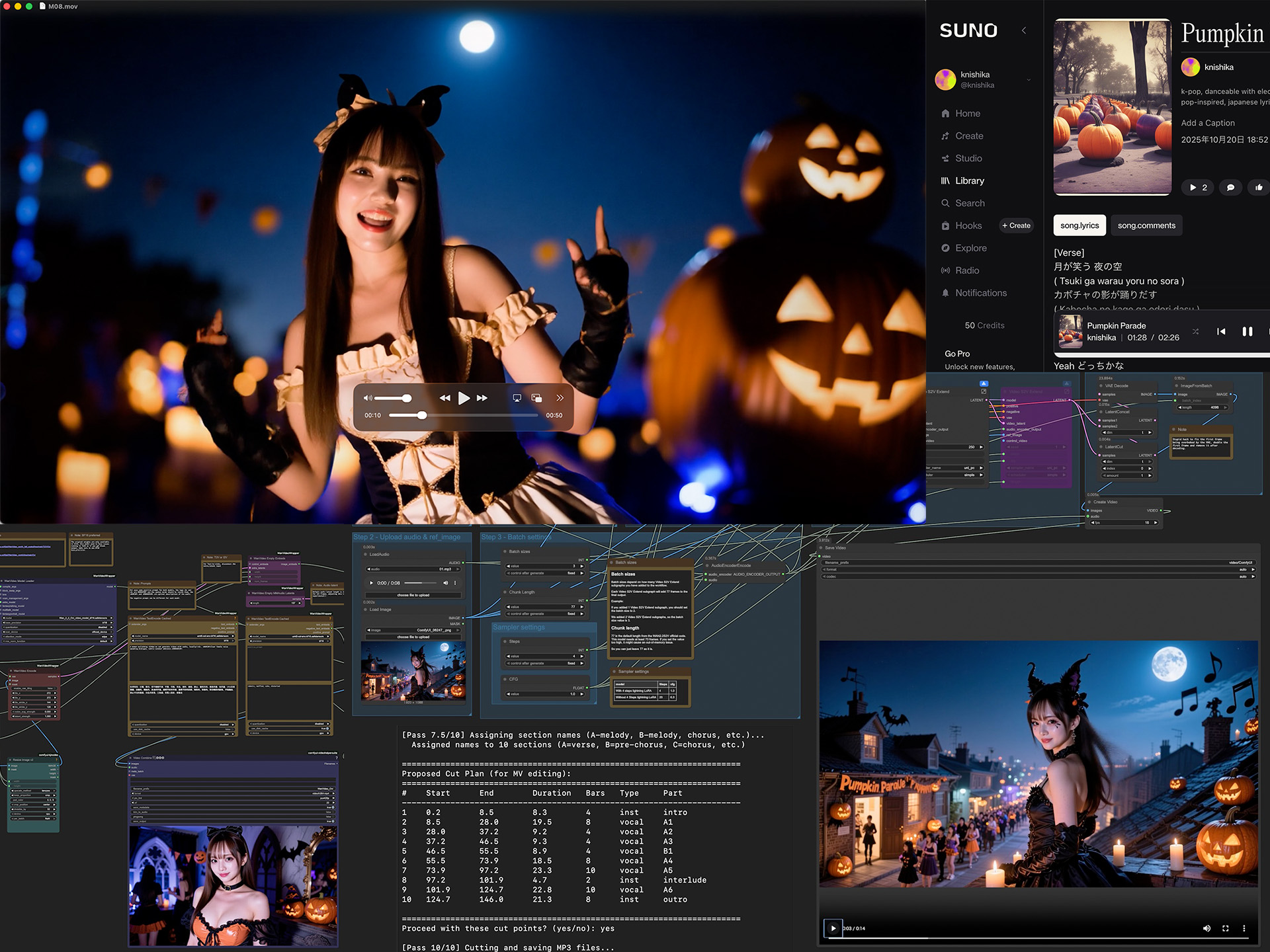
MVを作るなら楽曲がないと話にならない。これに関しては定番のSUNOを使った。与えたプロンプトは、
k-pop, happy ハロウィン dance Japanese song
たったこれだけ(笑)。いくつかできたのだが気に入った一曲は“Pumpkin Parade”。
実は作った順番は後述するOmniHuman Proが先、こちらが後だったので、どう作ったのかは後にして結果だけ。イントロとAメロ(途中まで)をそれぞれ音源と画像を別に用意し生成、できた動画をマージしている。RTX5090で720p/16fpsの15秒が420秒。加えてかなり熱を出し、重い処理となる。
いかがだろうか?指先など細かい部分は怪しいものの、歌詞に合わせたリップシンクはもちろん、リズムに乗って体も動き、MVっぽくなっている。これがローカルのAI PCで生成可能になるとは、少なくとも今年前半では思っても見なかった。
Wan2.2-S2Vはある程度できても……ということもあり、実は先にSousakuAIのAIアバター(OmniHuman Pro)を使っている。このサービスが主に扱っているのはByteDance系のモデル(Sora2やVeo 3.1にも対応)。日本国内に拠点を持ち、画像/動画ともNSFW対応という、商用としては珍しい特徴もある。
AIアバターの仕様は、
- 参照画像1枚。生成する動画はこれに準拠
- セリフの場合はプロンプト入力可能。音源がある時はMP3などをアップロード(最大30秒=動画の尺)
- キャラクターの動作は別途プロンプトで指定
となっている。つまりMVを作るにはまず、音源をイントロ、Aメロなど、キリがいいところでカットする必要がある(ただし最大30秒)。
何かGUIなツールがあれば簡単なのだが、手元になく、iMoveやQuickTime Playerで切るのも面倒……ということで、Claude Codeを使ってプログラムを作り、AI的にカットすることにした(笑)。指示はこんな感じだ。
#### 6パス構成
1. Pass 1: BPM・ビート・小節検出
2. Pass 2: 小節ごとの音響特徴量抽出(RMSも含む)
3. Pass 3: セクション境界検出
4. Pass 4: セクション長調整(隙間なし)
5. **Pass 5: 境界微調整(静かな場所を探す)** ★新規
6. Pass 6: MP3カット・保存
Pass 5は、ジャストで切るとビートが乗ることもあり、マージするとポップノイズが出るため。従って前後で音量の一番低いところでカットするようにしている。実際解析した結果はこの通り。これでちょうどいい感じにカットしたMP3の用意はできた。ただし、このAI判定によるMP3カッター自体はまだ未完成。曲によっては動かなかったりする。
次に映像に使うリファレンス画像。これはClaudeを使い、歌詞から印象的な部分を4つ選び、それをUpscale(想像)しつつプロンプトにしてもらった。結局使ったのは3つのみだったが、これはこれで面白かった(笑)。
また今回は使わなかったが、たとえば同一シーンの別カットが欲しい時はQwen-Image-Edit-2509、SeeDream4、Nano-Bananaなど画像編集系で作れば簡単だ。
MVは曲丸ごとだと2分26秒。いろいろ大変なので、イントロ、Aメロのみで構成することにした。結果は以下の通り。
いかがだろうか?楽曲、画像、映像すべてAI生成のMVとなる。正直細かいところがまだまだで、修正したいのはやまやまなのだが、これをし出すと時間もクレジットも溶けてしまうので(笑)、いったんここで止めておきたい。
この状態でもWan2.2-S2V版と比較するとぐんと良くなっているのが分かる。オープン版が追いつくのは半年後?1年後?いずれにしても後一歩という感じだ。
そしてちょうど執筆中に興味深い情報が飛び込んできた。ControlNetやFooocus、FramePackなどを作った鬼才、lllyasviel氏からFramePackにコメントがあり、
At this moment, our todo lists are mainly newer stuff in the post sora2/veo3.1 era so slower updates are expected.
現時点では、(FramePackの)ToDoリストは主にsora2/veo3.1以降の新しい作業のため、更新ペースは遅くなる見込みです。
とのこと。ローカルAI PCでSora2っぽいのが動くのは意外と近いかもしれない。楽しみだ!
以上、前半は2023年から最新の動画生成AI情報。後半はAIだけでMVを作るチャレンジをご紹介した。秋の夜長+ハロウィンでこういう楽しみ方も一興ではないだろうか。



