GPT-4oに近い性能で80億パラメータのオープンAIモデル「Rnj-1」をEssential AIが発表、CEOはTransformerを発明したチームの一員
オープンソース志向のAI企業・Essential AIが、言語モデル「Rnj-1」を発表しました。Rnj-1は80億パラメータで最大3万2000トークンの長文コンテキストを扱えるように設計されているほか、同クラスのオープンウェイトモデルと比べてコード生成や科学的推論の分野で高い性能を示しています。
Essential AI
https://essential.ai/research/rnj-1Today, we’re excited to introduce Rnj-1, @essential_ai's first open model; a world-class 8B base + instruct pair, built with scientific rigor, intentional design, and a belief that the advancement and equitable distribution of AI depend on building in the open.
We bring… pic.twitter.com/VpUHent2w8
— Essential AI (@essential_ai) December 6, 2025
Essential AIはアメリカのAI企業で、高度なAI技術の生産や流通が少数の企業によってコントロールされていることを懸念し、AIのブレイクスルーを世界規模で推進・加速するためのオープンプラットフォームを構築することを目標に掲げています。CEOを務めるアシシュ・ヴァスワニ氏は、GoogleでTransformerを開発したチームの一員であり、Transformerが世に出ることとなった論文「Attention Is All You Need」の共同著者の1人です。
ジェネレーティブAIの進歩に大きな影響を与えた「Transformer」を開発した研究者らはなぜGoogleを去ったのか? - GIGAZINE
そんなEssential AIが2025年12月6日に発表した「Rnj-1(レンジワン)」は、オープンソースに貢献する言語モデルとして、世界クラスのベースモデルと命令調整された大規模言語モデルを組み合わせています。Rnj-1という名前は、インドの伝説的な数学者であるシュリニヴァーサ・ラマヌジャンに由来しているそうです。
Rnj-1は基礎モデルと、命令に従うよう微調整されたInstructモデルのペアで構成されています。Rnj-1はGoogleのオープンソース大規模言語モデル「Gemma 3」のアーキテクチャを踏襲した80億パラメータモデルで、長文対応のための技術である「YaRN」を採用することで、最大3万2000トークンにわたる長文コンテキストを処理できる設計となっています。これにより、長い文章やドキュメントの読み取りのほか、長時間の会話やマルチステップの対話を必要とするタスクで有利に働きます。
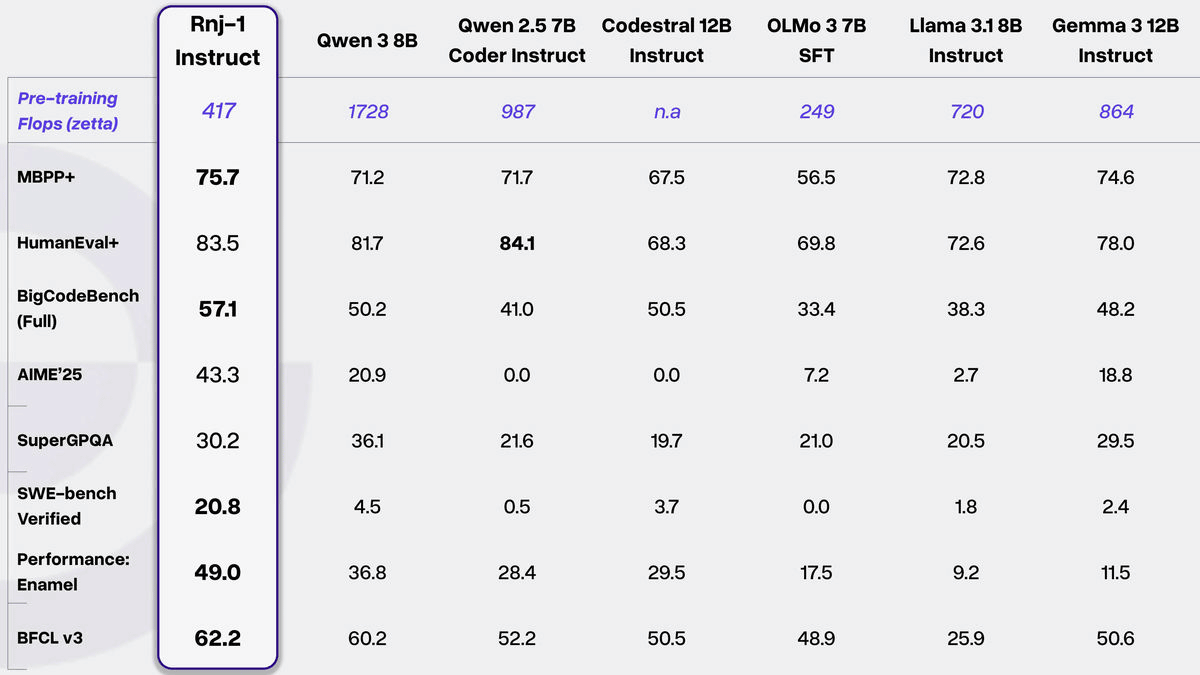
また、アルゴリズムコード生成タスクやより広範なコーディングタスクにおいて、Rnj-1 BaseとInstructはどちらも、同規模の最高クラスのオープンウェイトモデルと同等の性能を発揮するほか、200億パラメータのモデルなどさらに大規模なモデルよりも優れたパフォーマンスを発揮したことが報告されています。さらに、Essential AIが実現を目指す能力の1つであるエージェントコーディングにおいて群を抜いた性能を発揮し、エージェントの能力を測定するSWE-benchのbashのみのモードにおいて「20.8%」のスコアを記録しています。Essential AIは他のAIモデルのスコアをもとにRnj-1がGemini 2.0 FlashやGPT-4oと同等クラスの性能を発揮したとアピールしています。
Rnj-1は数学・科学問題の解決能力も優れています。「大学から大学院レベルの数学的・定量的推論能力」を測る「Minerva-MATH」では、同規模のオープンウェイトベースモデルと同等の性能を記録しました。また、「生物学、物理学、化学の分野を扱った、博士課程レベルの難しい問題」である「GPQA-Diamond」においては、同規模のモデルの中で最高に近い結果が示されています。 さらに、Rnj-1は学習後および推論時において「量子化」に耐性があるよう設計されています。通常は、より軽い計算方式(低精度)を選択すると計算速度が上がる一方で答えが乱れやすくなりますが、Rnj-1は計算の精度を16bit→8bit→4bitと落としても、ほぼ同じ品質を保ったまま処理速度を大幅に上げられるという特徴があります。これにより、大量の文章を一気に処理するような状況では、1秒あたりに生成できる文字量(トークンスループット)が大きく伸びるという利点があります。
ヴァスワニCEOは「私たちは、最初のフラッグシップモデルであるRnj-1を共有できることを、非常に興奮して誇りに思います。Rnj-1は、驚異的なチームによる10か月間の懸命な努力の集大成です」と述べています。また、Essential AIのヤシュ・ヴァンジャニ氏は「Rnj-1はEssential AIにとって大きなマイルストーンで、20人の小さなチームでどれだけ前進できるかを示しています。AI分野で最高の人たちと一緒に働けたのは光栄です!」と語りました。
We are beyond thrilled to share our first flagship models, Rnj-1 base and instruct 8B parameter models. Rnj-1 is the culmination of 10 months of hard work by a phenomenal team, dedicated to advancing American SOTA OSS AI.Lots of wins with Rnj-1.
1. SWE bench performance close… https://t.co/ZYKOj4zmXr
— Ashish Vaswani (@ashVaswani) December 6, 2025
Rnj-1はApacheライセンスバージョン2.0に基づいてライセンスされており、Hugging Faceでダウンロード可能です。ヴァスワニCEOによると、近日中にRnj-1の技術レポートも公開予定とのこと。今後の展望として、より長いコンテキストを処理できるようモデルの能力を拡張・強化、AIのトレーニングに必要なメモリ使用量を抑えて計算速度を上げる「低精度トレーニング」の実現、圧縮理論の推進やシミュレートしたいプログラム動作の種類と範囲の拡張などに注力していくと語っています。
EssentialAI/rnj-1 · Hugging Face
https://huggingface.co/EssentialAI/rnj-1EssentialAI/rnj-1-instruct · Hugging Face
https://huggingface.co/EssentialAI/rnj-1-instructRnj-1について、自然言語処理のコンサルタントおよび研究者であるKalyan KS氏は「Rnj-1はアメリカで構築された最高のオープンソースLLMの可能性があります。しかし、最近リリースされたMinistral 3 8B instructとの比較が欠けています」と評価しています。
Rnj-1, possibly the best open-source LLM built in USA.Interesting, Rnj-1's architecture is similar to Gemma 3, except that it uses only global attention, and YaRN for long-context extension.
But, comparison with the recently released Ministral 3 8B instruct model is missing… https://t.co/K8JpBYpFHh
— Kalyan KS (@kalyan_kpl) December 6, 2025
・関連記事 ジェネレーティブAIの進歩に大きな影響を与えた「Transformer」を開発した研究者らはなぜGoogleを去ったのか? - GIGAZINE
Googleが単一のGPUで実行できる中では過去最高の大規模言語モデル「Gemma 3」を発表 - GIGAZINE
高性能オープンソースAIモデル「Mistral 3」登場、NVIDIAとも提携して最適化&多用途に対応したファミリーを展開 - GIGAZINE
DeepSeekが数学的推論に特化したAIモデル「DeepSeek-Math-V2」をリリース、国際数学オリンピックで金メダルを取れるレベルの正答率を記録 - GIGAZINE
Alibabaの視覚言語AIモデル「Qwen3-VL」は2時間ある映像に挿入されたフレームを99.5%の精度で特定可能 - GIGAZINE



